
Der Anfang einer langen Kette – Verkaufsbezogene Analysen
Früher oder später wird es dazu kommen, dass man sein Produktportfolio klassifizieren, das heißt in Gruppen einteilen sollte. Eine weit verbreitete Methode ist die sogenannte ABC-Analyse (Wertanteil) , die in manchen Fällen um ein XYZ (Schwankungsteil) erweitert wird. In einem ausführlichen Beitrag werden wir eine dynamische ABC(D)-XYZ Analyse erstellen, die sehr einfach aktualisierbar sein wird. Üblicherweise kommt in dieser Art von Analysen das Pareto-Prinzip zum Tragen. Dieses hat als Kernaussage:
80% der Ergebnisse lassen sich mit 20% des Aufwands erreichen. Die restlichen 20% der Ergebnisse bedürfen daher 80% des Aufwands.
Im heutigen Post möchten wir daher eine Kennzahl errechnen, die im Verlauf einer Portfolio-Klassifizierungsaufgabe ergänzend zur Hilfe kommt: der durchschnittliche Abstand zwischen zwei Aufträgen in Tagen.
Wobei hilft uns diese Kennzahl? Zusammen mit anderen ihrer Art, die wir zusammen erstellen werden, lässt sich Aufschluss darüber geben in welcher Frequenz Materialien bestellt werden. Schlussendlich wollen wir aus einer gesamtheitlichen Portfolio-Klassifizierung natürlich Supply Chain Strategien wie beispielsweise Make-to-Stock (MTS) vs. Make-to-Order (MTO), Reorder point (ROP) oder Sicherheitsbestandsvorgaben (SB) ableiten. Da eine Supply Chain, beziehungsweise ein Portfolio keine statische, in Stein gemeißelte Geschichte sind, möchten wir die Aktualisierung der Daten so schmerzfrei und automatisiert wie möglich gestalten. Sie haben es denke ich mal geahnt, dass Power Pivot hier genau das richtige Werkzeug ist.
Das Measure – Avg_Tage_zw_ORD
Zu Beginn dieses Teils werde ich das gesamte Measure ablaichen, wie gewohnt debuggen wir uns von Innen nach Außen, sodass wir alle dasselbe Verständnis der Wirkweise haben:
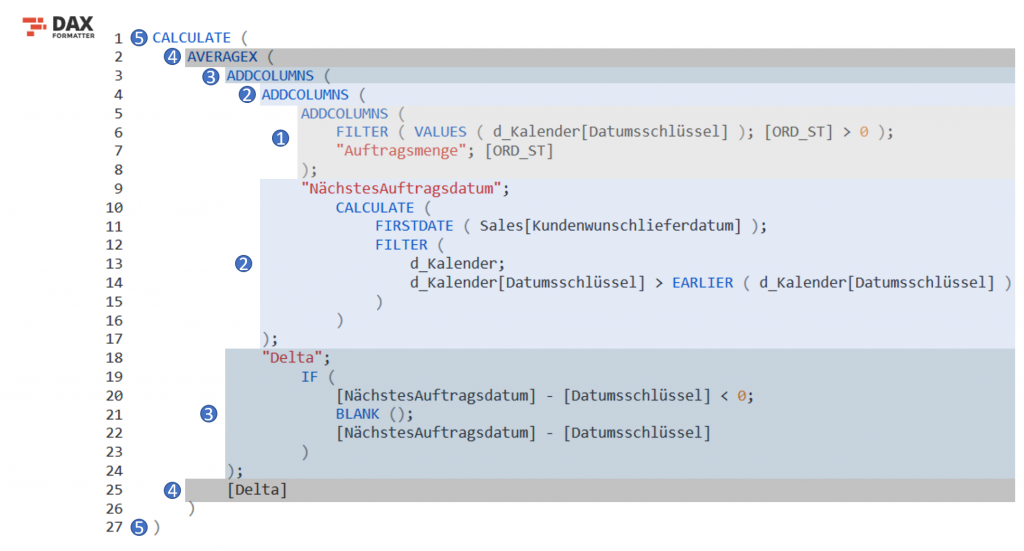
Im ersten Moment vielleicht etwas erschlagend, aber wenn es in Scheiben zerschnitten wird kommen wir gemeinsam dahinter. Sollte an dieser Stelle ein erfahrener DAX-Entwickler oder Entwicklerin den obigen Code lesen, Verbesserungsvorschläge oder Anregungen haben, freue ich mich selbstverständlich über eine Mail, denn ich möchte auch noch einiges lernen. Danke im Voraus.
Die innerste Tabelle des Ausdrucks
Wir beginnen mit Scheibe (1):

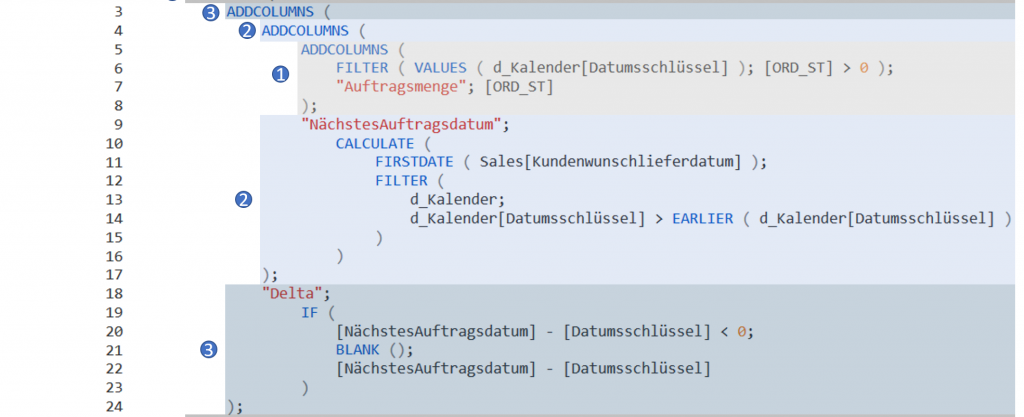
Die Basis unseres Measures bildet eine virtuelle, einspaltige Tabelle der Datumsschlüssel, die sich in unserer Dimensionstabelle d_Kalender befindet. Mithilfe von VALUES wird diese erstellt. VALUES wiederrum ist Bestandteil einer FILTER-Funktion, die nur die Tage zulässt, an denen auch tatsächlich eine Auftragsmenge im Auftragsbuch stand. Da FILTER eine Tabelle als Ausgabewert erstellt, erfüllen wir den ersten Parameter der Funktion ADDCOLUMNS.
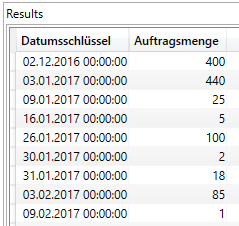
Als kleine geistige Stütze habe ich unserer Datumsschlüsselspalte eine Spalte mit der Bezeichnung Auftragsmenge hinzugefügt, sodass wir sehen, dass die FILTER Anwendung funktioniert hat. Ich recycle dabei unser Measure [ORD_ST], dass die Auftragsmenge in Stück wiedergibt. Wunderbar, hiermit haben wir die Erklärung des ersten Schritts abgeschlossen und bewegen uns eine Stufe nach oben.
Die kritische Berechnung der zweiten Stufe
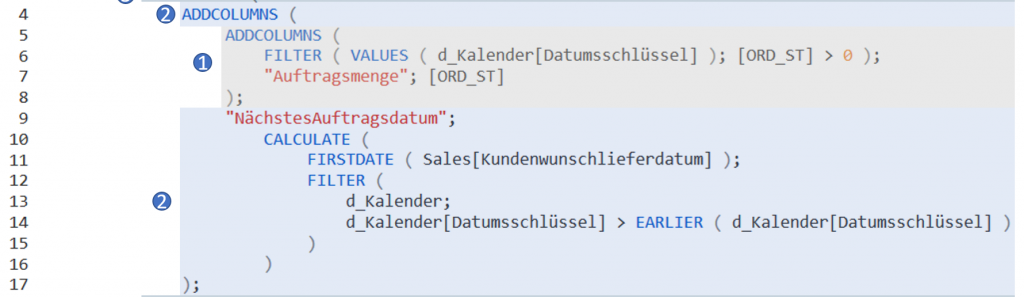
Es kommt erneut ADDCOLUMS zum Einsatz, wobei wir an dieser Stelle auf unsere “Grundtabelle” aus Schritt 1 aufbauen möchten. Es wird die Spalte “NächstesAuftragsdatum” rechts an die Tabelle angefügt. Diese soll uns am Ende aller Tage ausgeben, an welchem Tag der nächste Auftrag eingelastet wurde. Sprich wenn Auftrag 1 für Produkt X am 27.03.2019 eingebucht wurde und Auftrag 2 am 06.05.2019, soll uns Power Pivot den 06.05.2019 in die Spalte “NächstesAuftragsdatum” auf Höhe des 27.03.2019 einspielen. Wichtig hierbei: Wenn an einem Tag mehrere Aufträge gebucht sind, gelten diese als ein Event. Erst wenn wirklich ein Mindestabstand von einem Tag im vorhandenen Berechnungskontext vorherrscht wird dies gemessen. In Ordnung, gehen wir die Formel durch:
CALCULATE (
FIRSTDATE ( Sales[Kundenwunschlieferdatum] ),
FILTER (
d_Kalender,
d_Kalender[Datumsschlüssel] > EARLIER ( d_Kalender[Datumsschlüssel] )
)
)
Wie häufig in unserem Leben fängt eine jede Formel mit CALCULATE an. In diesem Fall benötigten wir die Mutter aller Funktionen um im späteren Verlauf einen Filter anzuwenden. Lassen Sie uns aber erst einen Blick auf FIRSTDATE riskieren. Wie man aus dem Namen relativ einfach ablesen kann wird die Funktion wohl irgendein erstes Datum ermitteln. FIRSTDATE gehört zur Kategorie der Time Intelligence Funktionen, die sofern die Datumstabelle d_Kalender für Power Pivot als solche erkennbar ist, mit Datum- und Zeitwerten arbeiten kann. Sie ermittelt demnach das erste Datum im aktuellen Kontext. Lassen Sie uns probieren was FIRSTDATE ohne den anschließenden FILTER-Ausdruck macht:
Die Formel sieht dann wie folgt aus:
CALCULATE ( FIRSTDATE ( Sales[Kundenwunschlieferdatum] ))
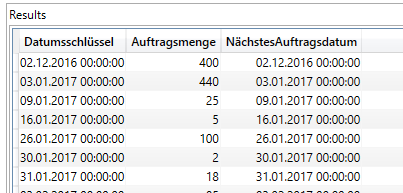
Wir sehen, dass uns dasselbe Datum ausgegeben wird, welches wir in der ersten Spalte vorliegen haben. FIRSTDATE arbeitet zwar richtig und gibt den ersten Tag des Auftrags, der an diesem Tag eingegeben wurde wieder, allerdings bringt uns das keinen Meter weiter. Wir müssen also wohl oder übel in die Untiefen des FILTER-Ausdrucks abtauchen. Vorab aber eine kleine Inforeihe:
- FILTER erzeugt eine virtuelle Kopie der Tabelle d_Kalender und kreiert automatisch einen Zeilenkontext. Das bedeutet, dass Power Pivot “weiß” in welcher Zeile der Tabelle es sich befindet. FILTER gehört, ähnlich wie AVERAGEX und andere X-Funktionen zu den Iterationsfunktionen, die in der Lage sind eine Tabelle Zeile für Zeile abzugrasen.
- Sales[Kundenwunschlieferdatum] und d_Kalender[Datumsschlüssel] befinden sich in einer aktiven Beziehung
- Demnach werden sich die Filter entlang der Beziehung auf den Ausdruck FIRSTDATE ( Sales[Kundenwunschlieferdatum] ) der CALCULATE Formel auswirken!
- Grundsätzlich sollten wir versuchen einen FILTER-Ausdruck auf eine Dimensionstabelle anzuwenden. Diese haben in der Regel eine überschaubare Zeilenzahl. Die Sales Tabelle mit rund 245.000 Zeilen ist zwar noch kein wirkliches Monstrum, hat aber dennoch das Potential eine Berechnung zu verlangsamen. Bitte immer beachten!
- Außerdem bedenken wir: Es wird erst gefiltert und dann gerechnet!
Nach Verdeutlichung der wichtigen Parameter bewegen wir uns nun aber wirklich in Richtung des FILTER-Ausdrucks, den wir an sich auch noch mal zerstückeln möchten. Beachten Sie bitte, dass ich hier versuche die Materie mit Verständniskrücken zu erklären. Die VertiPaq Engine von DAX arbeitet im Hintergrund anders, die Erklärung dessen wäre aber wohl zu technisch.
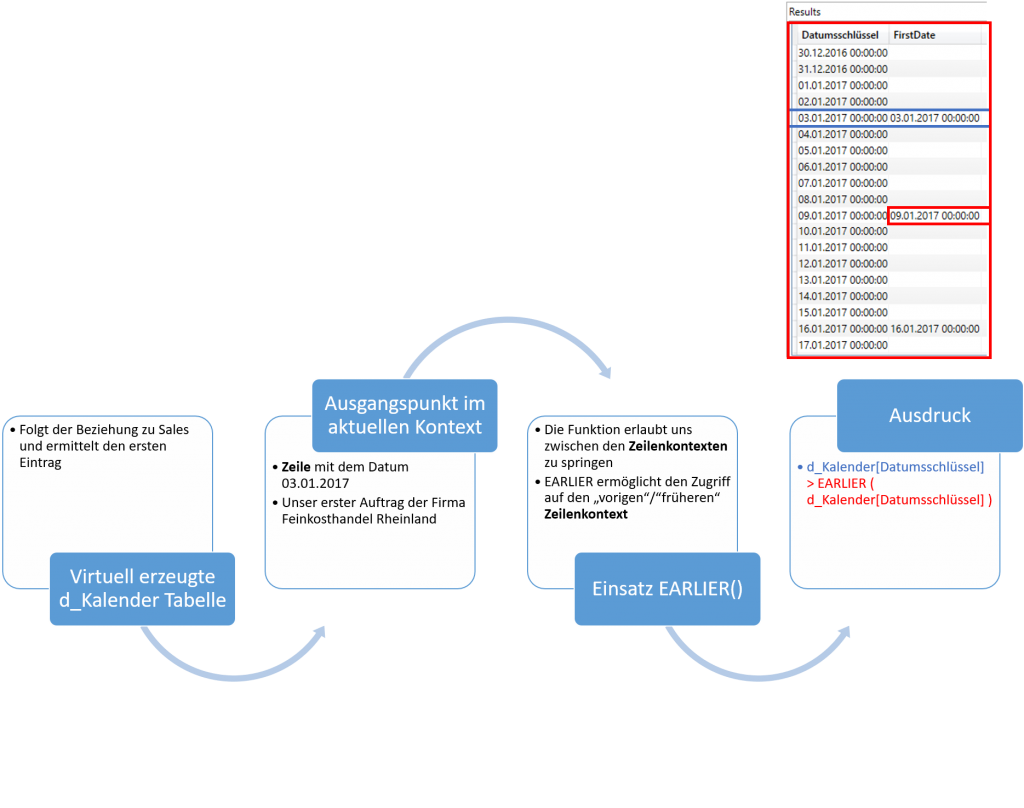
Der eigentliche Star im FILTER-Ausdruck ist EARLIER. Wie zuvor beschrieben erzeugt FILTER als Iterationsfunktion automatisch einen Zeilenkontext in der virtuellen Tabelle. Ich habe mal das erste Auftragsdatum, den 06.12.2016 weggelassen, da die Erklärung dann deutlicher wird. Gehen wir einfach davon aus, dass am 03.01.2017 unser erster “richtiger” Auftrag war. Im Bild oben rechts habe ich die gesamte Kalendertabelle als solche ausgeben lassen. Wir sehen, dass nur manche Zeilen gefüllt sind, nämlich die, in denen in der Sales-Tabelle ein Eintrag vorhanden ist. Wie also verlassen wir die Zeile, die blau umrandet ist?
Genau hier kommt EARLIER zum Einsatz. Diese Funktion ermöglicht es uns den aktuellen Zeilenkontext zu verlassen und auf die “gesamte” d_Kalender-Tabelle und deren Datumswerte zuzugreifen (roter Kasten). Somit kommen wir auf den letzten Schritt zu sprechen, der den Ausdruck von FILTER betrifft. Dieser liest sich, wenn wir alles zusammensetzen wie folgt:
Gib mir eine Tabelle wieder, die Datumswerte in Sales[Kundenwunschlieferdatum] enthält, die größer sind als das Datum des aktuellen Zeilenkontextes. Diese wird dann an den Ausdruck FIRSTDATE( Sales[Kundenwunschlieferdatum] ) weitergegeben. In der Zeile mit dem Datumswert 03.01.2017 käme demnach 09.01.2017 als Ergebnis raus, da dies das erste Datum der erzeugten Tabelle ist, dass größer als der 03.01 ist und einen Eintrag in der verknüpften Sales Tabelle hat.
Wenn wir nun zu unserem fehlgeschlagenen Versuch mit FIRSTDATE (Ankerlink) zurückkehren möchten und es diesmal besser machen, indem wir die komplette CALCULATE Verformelung ausführen, erhalten wir die richtige, virtuelle Tabelle:

Ein Traum. Somit haben wir die zweite Scheibe des Measures (Ankerlink) erfolgreich debugged und hoffentlich auch verstanden.
Die dritte Scheibe – eine einfache Subtraktion
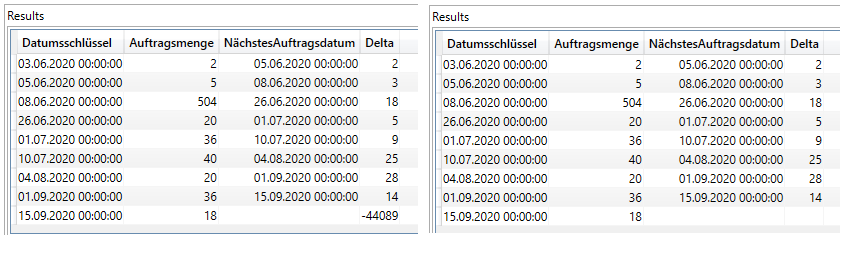
Erneut kommt ADDCOLUMNS zum Einsatz, da wir eine weitere Spalte hinzufügen möchten, die uns das Delta zwischen den beiden Datumswerten ausgibt. Wir gehen in diesem Fall eigentlich vor wie in der “normalen” Excel-Welt und bilden die Differenz zwischen der Spalte [NächstesAuftragsdatum] und [Datumsschlüssel]. Die IF-Verschachtelung soll uns lediglich davor bewahren, dass in der Zeile mit dem letzten Auftragsdatum kein hoher negativer Wert steht, der den Durschnitt versauen würde:
Der Durchschnitt verpackt im warmen CALCULATE-Mantel
Scheibe 4 und 5 fassen zusammen, da sie am Ende reine Formalität sind. Führen wir uns noch mal kurz das Ziel der Aufgabe vor Augen. Wir möchten wissen, was der durchschnittliche Abstand zwischen zwei Kundenaufträgen im aktuellen Filterkontext ist. Demnach müssen wir letztendlich den Durchschnitt unserer virtuellen Spalte “Delta” ermitteln.
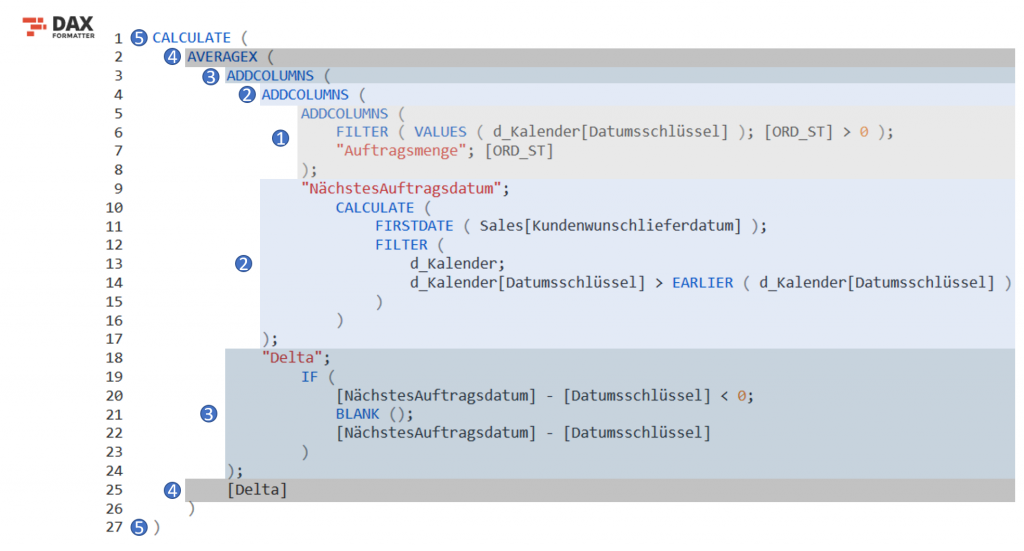
AVERAGEX verlangt im ersten Parameter nach einer Tabelle, die es als bekennende Iterationsfunktion durchlaufen möchte. Diese Tabelle haben wir in mühsamer Kleinstarbeit erstellt, besprochen und verinnerlicht, sodass wir diese mit gutem Gefühl übergeben. Im Ausdruck, folglich zweiten Parameter überreichen wir Spalte Delta über die der Mittelwert gebildet wird. Als Sahnehäubchen schließen wir mit einem CALCULATE ab und schwenken in die Excel-Oberfläche um einen Blick auf die PivotTable mit zwei Szenarien zu werfen:
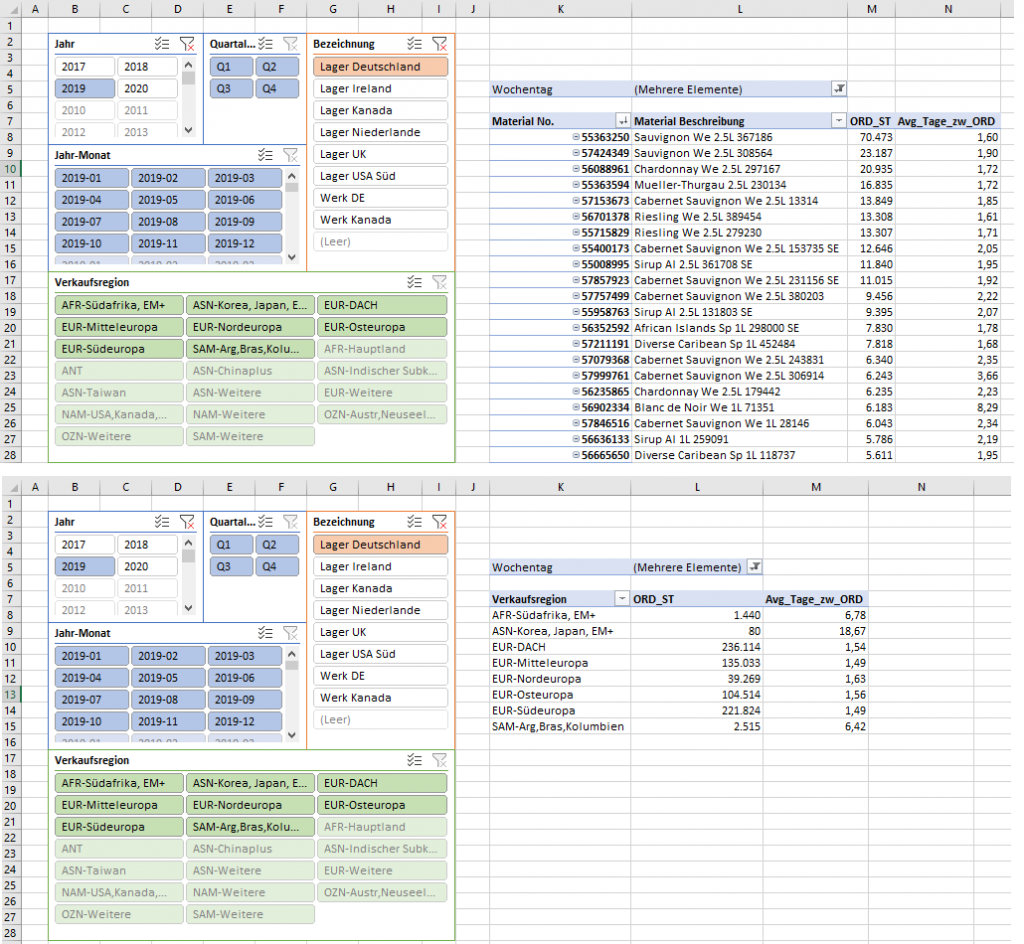
Ich nehme jetzt mal die beiden ersten Zeilen als Beispiel zur Hand:
- Der Filterkontext der Slicer/dem Berichtsfilter ist in beiden Beispielen gleich:
- Jahr: 2019
- Distributionsknoten: Lager Deutschland
- Wochentage <> Samstag und Sonntag
- 55363250 – Sauvignon We 2.5L 367186
- Im Schnitt erhalten wir 2019 alle 1,6 Tage einen neuen Auftrag im Lager Deutschland für das oben aufgeführte Material
- AFR-Südafrika, EM+
- In dieser Verkaufsregion erhalten wir alle 6,78 Tage einen Auftrag, der aus dem Lager Deutschland in 2019 bedient werden sollte
Mit Hilfe unseres Measures können wir nun anfangen herauszufinden, wie die Auftragsfrequenz in verschiedenen Filterkontexten ist. Dies hilft uns detaillierte, verkaufsbezogene Analysen zu erstellen. Wir werden dieses Measure auch, wie versprochen in einer kommenden ABCD-Analyse wiederverwerten!
Viel Erfolg bei ihrer Datenanalyse! Bis neulich.
#Formelwissen: ADDCOLUMNS ; VALUES ; CALCULATE; AVERAGEX ; EARLIER

No responses yet