
Hinzufügen der Tabelle mit Sicherheitsbeständen
Im Zuge dieses Beitrags ist es mal wieder an der Zeit unser Datenmodell aufzuwerten und eine neue Tabelle zu integrieren. In diesem Fall soll es sich um Sicherheitsbestände handeln, die bei einigen Produkten hinterlegt sind. Sicherheitsbestände sorgen für ein extra Polster im Bestand für den Fall von unvorhersehbaren Absatzschwankungen oder unsicheren Lieferzeiten auf der Rohstoffseite. Diese Bestände sollten im Idealfall immer auf Lager sein und nicht dauerhaft unterschritten werden, da sonst ihre Funktion nicht erfüllt ist.
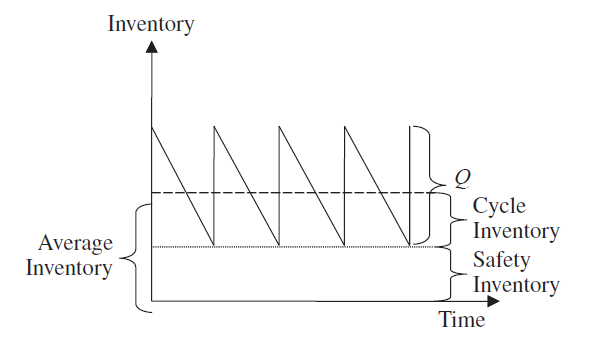
Das handelsübliche Sägezahndiagramm zeigt schön, dass die Sicherheitsbestände immer verfügbar sind und Nachschub genau rechtzeitig getaktet ist.
Zurück zu Power Pivot und unserem Datenmodell. Unter folgendem Link finden Sie wie üblich die Datei. Diese möchten wir über den bekannten Weg in unser Datenmodell hieven. Dazu befolgen wir die folgenden Schritte, die in der Galerie aufgezeigt sind:


Ein Blick in die Power Pivot Oberfläche sollte nun zeigen, dass die Tabelle da angekommen ist wo sie hingehört. Tabelle SiBe enthält neben den Produktnummern auch noch die Netzwerkknoten, in denen die Sicherheitsbestände hinterlegt sind. Beide Felder möchten wir mit Beziehungen verknüpfen:
- SiBe[Produkt] mit d_Material[Material No.]
- SiBe[Netzwerk-Knoten] mit d_Werke_Lager[Werk/Lager]
Was wir außerdem noch machen möchten ist, eine Datumsspalte der Tabelle SiBe hinzuzufügen, sodass wir in Analysen den Sicherheitsbestand auf Stand “Heute” sehen können und somit wissen, dass es der Aktuelle ist. Das ist nicht zwingend erforderlich, aber es hat mir in der Praxis durchaus seine Dienste geleistet.
Wir können die Spalte rechts neben “Eiserner Bestand” per Spalte hinzufügen in der Power Pivot Oberfläche anfügen. Diese verknüpfen wir mit d_Kalender[Datumsschlüssel]
Wunderbar. Die Vorkehrungen sind getroffen und jetzt können wir zur Tat schreiten.
Erstellung des Measures SiBe_ST
Wir haben zum aktuellen Zeitpunkt nur eine Spalte in der Tabelle SiBe, der wir für uns verwertbare Zahlen entlocken können, “Eiserner Bestand”. Mit Hilfe unserer Expertise erstellen wir nun das Measure (ST steht für Stück):
SiBe_ST:= CALCULATE ( SUM( SiBe[Eiserner Bestand]))
Das wirft jetzt nicht direkt Schweißperlen auf die Stirn, sondern reiht sich in die Kategorie der einfachen Measures ein. Gerne können Sie schon mal in einer PivotTable schauen, in welchen Werken wir Sicherheitsbestände (SBe) in welcher Höhe haben.
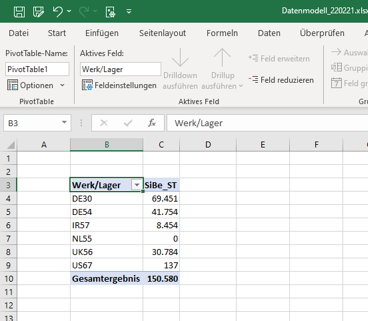
Augenschneinlich ist es so, dass wir in den Niederlanden ein Lager haben, das über keinerlei SB verfügt und in unserem US-Lager nur geringfügige Mengen anzufinden sind. Wir lassen das für den Moment mal im Raum stehen, da wir im Rahmen einer Ist-Situation agieren. In einem weiteren Blogpost werde ich die Sicherheitsbestände neu berechnen und das Netzwerk somit neu ausrichten. Aber für den Moment nehmen wir die aktuellen Werte als gegeben an.
Erläuterung der Aufgabe
Die Überschrift hat vielleicht schon ein bisschen darauf angespielt wo es in diesem Blogpost hingehen soll. Ich belasse es natürlich nicht bei der einfachen Aufgabe, sondern wir widmen uns der eigentlichen Sache. Aktuell haben wir die Informationen in welchem Werk für welches Produkt ein Sicherheitsbestand hinterlegt wurde. Wir möchten allerdings über einen gewissen Zeitraum wissen, ob dieser unterschritten wurden, wenn ja, wie oft, sodass wir Maßnahmen für die Zukunft ergreifen können, dass dies nicht mehr passiert.
Aus einem meiner vorigen Posts wissen Sie, dass unser Datenmodell eine Reihe von Bestandsdateien an unterschiedlichen Tagen enthält. Dies würde es uns nun ermöglichen zu überprüfen, wann wir den SB erreicht, unterschritten oder komplett aufgebraucht haben. Und genau das ist jetzt unser Ziel.
Das Produktbeispiel an dem wir uns detailliert an der Sache entlanghangeln stammt aus der Rubrik Meeresfrüchte und zeigt im unten aufgeführten Bild schon, dass wir den SB an manchen Tagen verletzt haben. Bitte beachten: Einige Zeilen sind ausgeblendet!
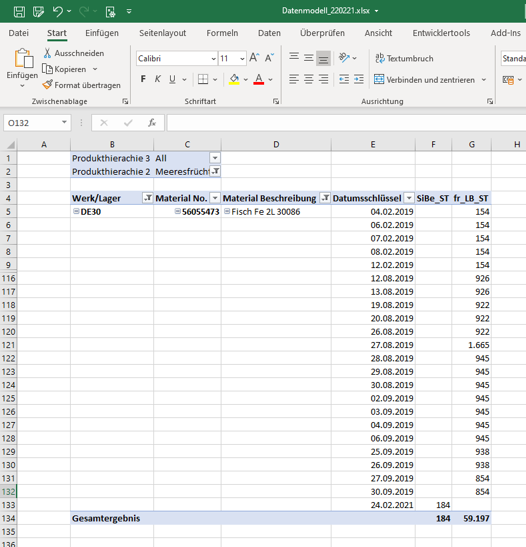
Wir werden demnach im Laufe ermitteln, wie viele Tage (an denen eine Bestandsmessung vorhanden ist) der SB unterschritten war.
Ermitteln der unterschrittenen Tage und neue Measures
Als Startpunkt der Aufgabenlösung möchten wir damit beginnen den Sicherheitsbestand auf alle Datumswerte zu legen an denen auch ein Lagerbestand vorhanden war. Dies ermöglicht es uns zu einem späteren Zeitpunkt den Lagerbestand (LB) und die Sicherheitsbestand (SB) zu verrechnen, somit die Differenz herauszufinden und unser gewünschtes Ergebnis zu erzielen.
Kurz vorab: Ich werde die einzelnen Schritte in der PivotTable veranschaulichen, wir benötigen aber eine virtuelle Tabelle zum Erfolg.
Verwendung von ALL() auf verschiedene Weise
Wir benötigen die Funktion ALL(), um den Filter der Datumswerte zu ignorieren und demnach den SB an allen Tagen einzuspielen. Die Formel unseres ersten Versuchs lautet:
SiBe_ST_ALL_1:=CALCULATE ( [SiBe_ST] ; ALL (d_Kalender))
Wie ich es bereits in meinem E-Book beschrieben habe, ist es Best-Practice bereits erstellte Formeln wiederzuverwenden, da man sich dadurch schnelle Änderungsmöglichkeiten einkauft und nicht alle Formeln eines Datenmodells durchsuchen muss wenn sich einige Parameter ändern. Lassen Sie uns einen Blick in die PivotTable riskieren:
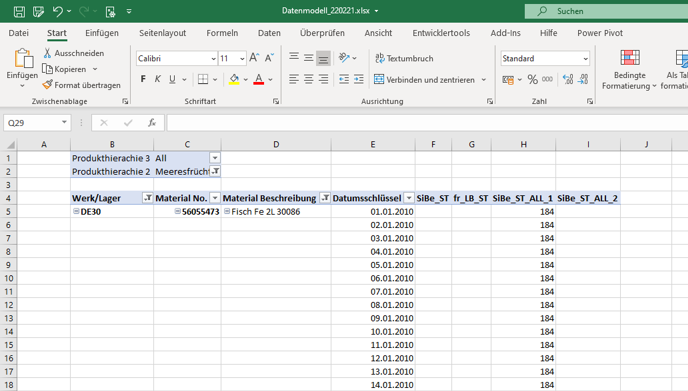
Wir sehen, dass ALL() in unserer Verformelung seinen Dienst verrichtet. Leider hilft mir das aktuell bei meiner Erklärung nicht, da an jedem Tag, der einen Eintrag in der Datumstabelle hat, der SB hinterlegt ist. Wir wissen, ALL() funktioniert, hilft mir an dieser Stelle aber nicht bei meiner Erklärung. Deswegen möchte ich Ihnen HASONEVALUE vorstellen und damit unseren zweiten Versuch einläuten:
SiBe_ST_ALL_2:= IF (
HASONEVALUE ( ‘Bestände'[Best_Datumsschlüssel] );
CALCULATE ( [SiBe_ST]; ALL ( d_Kalender ) );
BLANK ()
)
HASONEVALUE prüft, wie der Name schon verrät, ob sich in einer bestimmten Spalte Werte befinden. Das Ganze in einer IF-Verschachtelung verwendet, hilft uns das Bild klarer darzustellen und nicht die gesamte Tabelle d_Kalender zu öffnen.
Gesprochen würde die obige, zweite Formel nun fordern, dass, sofern ein Datumswert einen Lagerbestandseintrag in “Bestände” enthält der Sicherheitsbestand auch aufgezeigt werden soll. Ist dem nicht der Fall zeige BLANK(). Der Blick auf die PivotTable lässt uns nun zufrieden Grinsen:
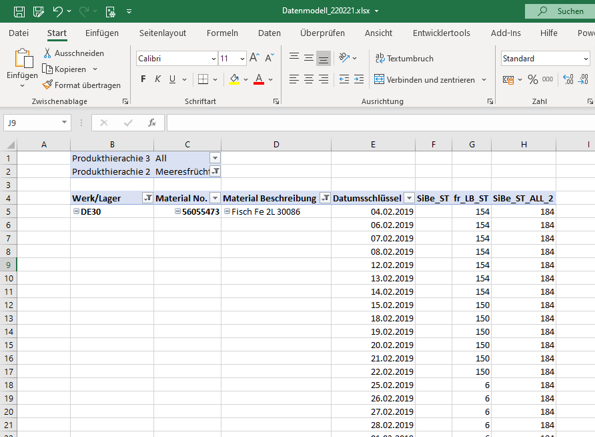
Wenn wir nun, wahrscheinlich in alter Excelmanier schnell eine IF-Verschachtelung bilden, bei der wir die Unterschreitungen als “1” wiedergeben, würden wir folgende Formel verwenden und folgende Ansicht erhalten:
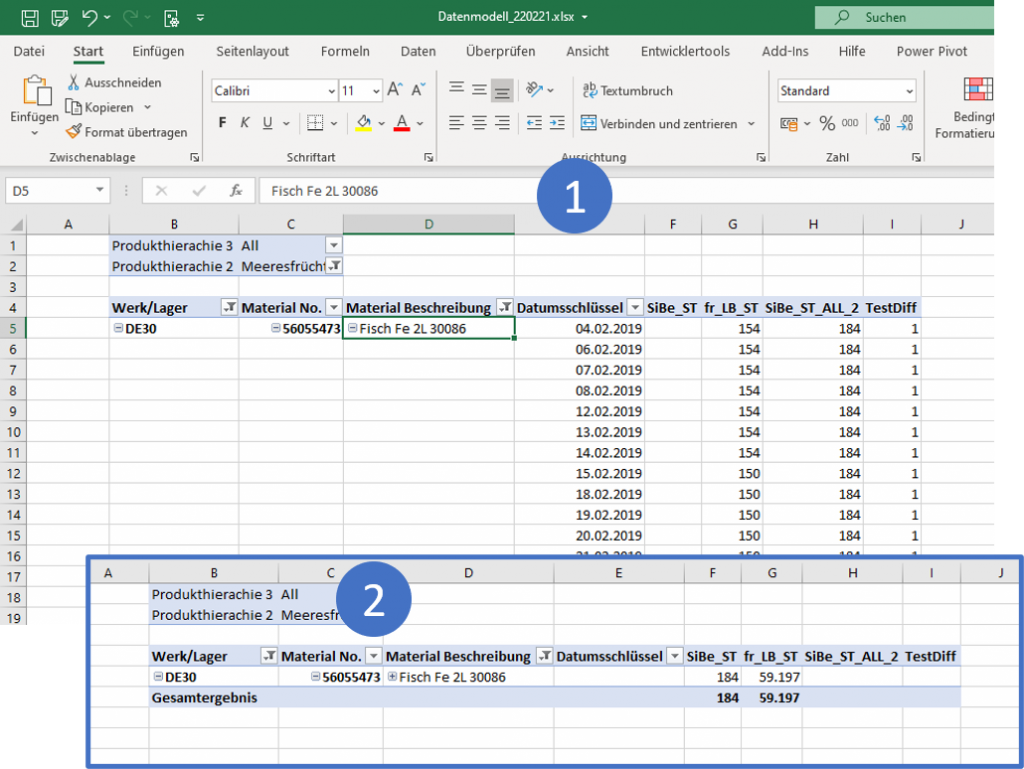
Wie wir eindrücklich sehen, funktioniert alles auf der Detailebene, aber dafür sind PivotTables nun mal nicht gemacht. Am Ende aller Tage möchten wir eher auf einer Lager/Werk-Material Ebene sehen, wie sich die Situation mit den Sicherheitsbestände darstellt, ohne jeden Tag einzeln beleuchten zu müssen. In der Aggregation herrscht in der PivotTable ein anderer Filterkontext. Diesen zu berücksichtigen ist eine essentielle Grundkenntnis und extrem wichtig im Verständnis von DAX. Wir müssen uns der Aufgabe demnach von einer anderen Seite nähern und bilden dazu eine virtuelle Tabelle.
Die virtuelle Tabelle
Im Grunde genommen bilden wir mit der Erstellung der virtuellen Tabelle das nach was ich vorhin in der PivotTable demonstriert habe, behalten dabei aber den gewünschten Detailgrad bei und haben somit auch bei späterer Aggregation die richtigen Werte.
T_unter_SB: CALCULATE (
COUNTX (
ADDCOLUMNS (
SUMMARIZE (
‘Bestände’,
d_Kalender[Datumsschlüssel],
d_Material[Material No.],
d_Werke_Lager[Werk/Lager],
“@LB”, [fr_LB_ST],
“@SB”, CALCULATE ( [SiBe_ST], ALL ( d_Kalender ) )
),
“@Diff”, [@LB] – [@SB]
),
IF ( [@Diff] < 0, 1, BLANK () )
)
)
Jetzt wird es schon ein wenig komplexer. Wir arbeiten uns wie gewohnt von Innen nach Außen und starten demnach mit SUMMARIZE. Mithilfe dieser Funktion greifen wir die, für uns aktuell, wichtigsten Spalten der “Bestände” Tabelle, die als erster Parameter von SUMMARIZE genannt ist. Wir konstruieren dieselben Spalten, die wir zuvor in der PivotTable hatten und beziehen uns dabei immer auf die Dimensionstabellen (“d_”). Wenn wir das Grundgerüst erzeugt haben, werden zwei Spalten angefügt. @LB recycelt unser vorhandenes Measure und wirft die Lagerbestände für Material X and Tag Y in Werk Z aus. Für dieselbe Kombination werden in Spalte @SB die Sicherheitsbestände hinterlegt.
Bitte beachten Sie, dass wir in diesem Fall kein HASONEVALUE benötigen, da wir auf einer zusammengefassten Version der Tabelle Bestände arbeiten und somit auch nur Datumswerte aus dieser Tabelle vorhanden sind. Wunderbar, die Basis steht.
Dieser Grundtabelle fügen wir nun per ADDCOLUMNS eine weitere Spalte hinzu. Sie fragen sich vielleicht warum wir die Differenz nicht direkt innerhalb von SUMMARIZE ermittelt haben. Leider kann man innerhalb der Basistabelle keine Spalten verrechnen. Daher sind wir auf ADDCOLUMNS angewiesen. Wir bilden also die simple Differenz mit [@LB]-[@SB]. Kleiner Satz zu dem “@” vor den Spalten. Immer wenn wir virtuelle Tabellen und dazugehörige Spalten erstellen, sollten wir ein “@” verwenden, sodass wir diese von physischen Tabellen im Datenmodell leichter unterscheiden können.
COUNTX als Iterationsfunktion verlangt im ersten Parameter nach einer Tabelle. Diese haben wir mit ADDCOLUMNS und SUMMARIZE erfolgreich erstellt und können diese nun verwenden. Im Ausdruck, also dem zweiten Teil von COUNTX, möchten wir nur die Werte mit einer 1 hinterlegen und später zählen in denen der Sicherheitsbestand auch unterschritten wurde. Den krönenden Abschluss macht wie immer CALCULATE und damit haben wir das Measure T_unter_SB fertiggestellt, wobei das T für Tage steht.
Wir gehen zurück in unsere PivotTable und vergewissern uns, ob alle Annahmen stimmen und das Ergebnis korrekt ist:
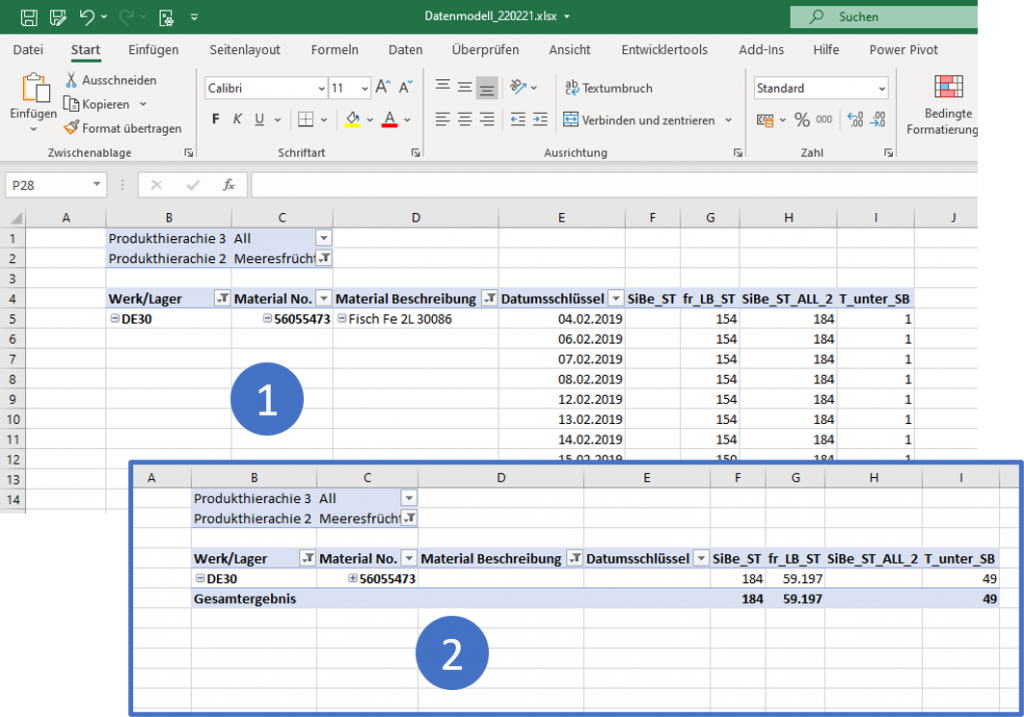
Unter Punkt 1 sieht noch alles so aus wie in der vorigen PivotTable, wenn wir aber in die Aggregation gehen (2), sehen wir dass nun auch alles korrekt berechnet wird und unser Measure tatsächlich brauchbar geworden ist. Sie können gerne einen genaueren Blick auf andere Materialien werfen und mit den Daten spielen.
Mithilfe einer solchen Tabelle wären natürlich auch Modifikationen der Berechnung denkbar, sodass wir vielleicht wissen möchten, wann ein kompletter Stock Out passiert ist, der Bestand also auf 0 sank, oder eine andere Grenze unterschritten hat. Dies könnte Beispielsweise eine Mindestmenge von einem Paket o.ä. sein. Der Fantasie sind dabei keine Grenzen gesetzt.
Bis bald!
#Formelwissen: HASONEVALUE ; ADDCOLUMS ; SUMMARIZE ; COUNTX ; BLANK;

No responses yet