
Klärung der Mysterien aus dem vorigen Teil der Reihe
Zunächst einmal wollen wir uns die PivotTable mit der Auswahl auf die Produktgruppe Gin noch mal vor Augen führen. Diese hat als offenen Punkt zur weiteren Klärung, dass vorherige Kapitel über Lagerbestandsmanagement abgeschlossen. Hier gibt es besonders mit Hinblick auf die Spaltenergebnisse der Durchschnitte noch den ein oder anderen Erklärungsbedarf:
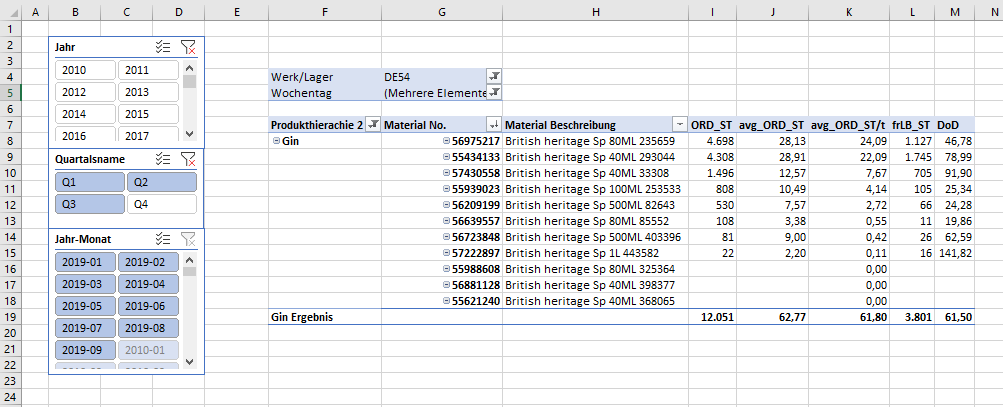
Das simple Überschlagen der Spalten J und K lässt bei den Gesamtergebnissen Zweifel aufkommen. Wie kann es sein, dass ein Mittelwert von 62,77 entsteht, wenn die jeweiligen Produktergebnisse nicht über 29 hinausgehen? Die gleiche Aussage trifft auf Spalte K zu. Befassen wir uns aber demnächst mit der durchschnittlichen Auftragsgröße.
An dieser Stelle kommt eine wichtige Eigenschaft von Power Pivot zum Tragen, die ich in meinem E-Book umfangreicher thematisiert habe. Jede Zelle einer (Power) PivotTable wird als Individuum betrachtet und unabhängig von anderen Zellen berechnet! Dabei wollen wir stets den Filterkontext in dem die Berechnung abläuft bedenken. Wenn Sie also bei Ergebnissen jeglicher Art ein bisschen ins Stocken geraten, stellen Sie sich bitte immer folgende Frage:
In welchem Filterkontext wird mein Measure/meine Zelle berechnet?
Welche Filter wirken also auf unser Teilergebnis 62,77?
- Werk/Lager: DE54 (Berichtsfilter)
- Wochentag: <> Samstag & Sonntag (Berichtsfilter)
- Datum: Jahr 2019, Monate Januar bis September (Datenschnitte/Slicer)
Der Filter der Materialnummern hat demnach keine Relevanz für das Ergebnis. In anderen Worten werden Produkte, die am selben Tag als Auftrag vorlagen aufsummiert und später als Basis für die Ermittlung des Mittelwerts genommen. Beispielsweise standen am 8 Januar 2019 folgende Materialien im Buch:
| Material No. | Material Beschreibung | ORD_ST |
| 55434133 | British heritage Sp 40ML 293044 | 80 |
| 56975217 | British heritage Sp 80ML 235659 | 78 |
| 56209199 | British heritage Sp 500ML 82643 | 30 |
| Summe | 188 |
Für die Berechnung des Spaltenergebnisses ist für Power Pivot in der virtuell erzeugten Tabelle aber ausschließlich die 188 zu “sehen”. Wenn es also mehrere Tage gibt, an denen das gleiche Phänomen auftritt, was klar der Fall ist, wird langsam deutlich warum sich der Mittelwert im obigen Filterkontext auf 62,77 beläuft. Um es abschließend in Stein zu meißeln, habe ich unter folgendem Link die virtuellen Tabellen, auf die sich Power Pivot im Fall der beiden Measures bezieht und die als Berechnungsgrundlage dienen, angefügt. Wir erinnern uns, dass diese auf der Granularität Tag der Datumstabelle beruhen.
Bestandsmessung über einen längeren Zeitraum, Integration mit Power Query und neue Measures
Ich hoffe, dass ein bisschen Licht ins Dunkel der Teilergebnisse gekommen ist. Wenn nicht, gehen Sie es in Ruhe noch ein, zwei Mal durch. Der Groschen ist bei mir mit der Zeit gefallen, und wird das bei Ihnen auch tun.
Wir wollen uns für den Moment wieder ein bisschen mit dem Thema Power Query und der Funktionalität, mehrere Dateien eines Ordners direkt ins Modell zu integrieren, beschäftigen. Als mehrjähriger Excel-Anwender haben Sie und ich uns durch unzählige Tabellen geschwungen, diese mit Sverweisen, PivotTables und was es sonst noch so Schönes gibt verbunden oder zusammengeführt. Eine Kollegin kommt rein, will schnell was von einem, man weicht von der eigentlichen Aufgabe ab und zack hat meinen einen Schritt im Zusammenführen vergessen, bemerkt dies aber vielleicht erst später. Der Stresslevel steigt.
Um dem Weg der Volkskrankheit des stressinduzierten Bluthochdrucks, hier in seiner besonders widerlichen Form Bürobluthochdruck entgegenzukommen, haben sich die Microsoft-Entwickler Power Query ausgedacht. Einmal richtig aufgesetzt, ist jedes Update mit neuen Dateien nur einen Knopfdruck entfernt.
Wenn Sie schon einige Artikel von mir gelesen haben, wissen Sie, dass ich anfangs Situationen ausschmücke, sodass der Text an sich lesbarer wird. Vorab der Link zu den Bestandsdateien. Früher oder später geht es aber los – und zwar jetzt:
Laden aller Dateien eines Ordners
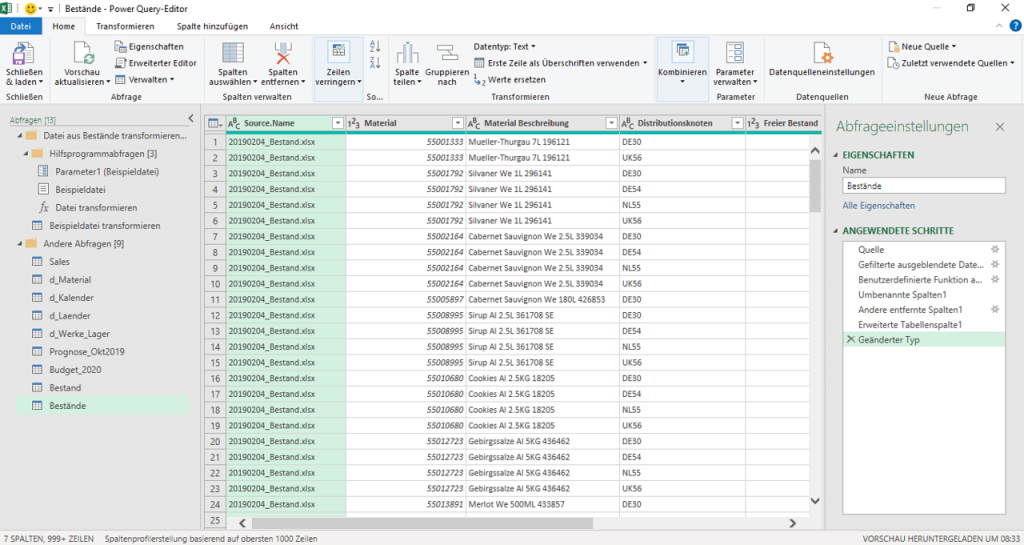
Wie üblich fangen wir damit an unserer Absicht Daten abrufen zu wollen nachzugehen und folgen zunächst den Schritten 1-3 des Screenshots:
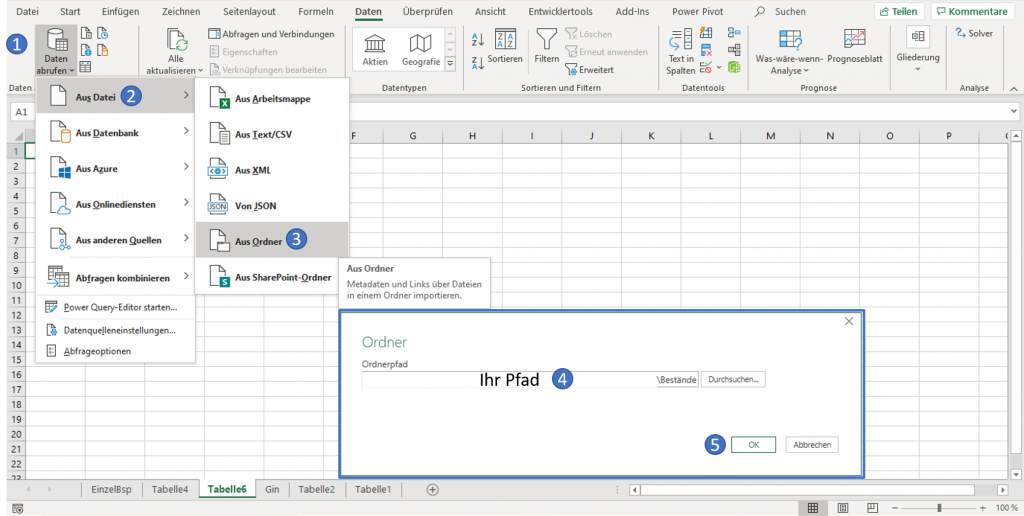
Wenn Sie Dateien heruntergeladen und lokal abgespeichert haben, dann sollte der letzte Bestandteil ihres Pfads genau dort hindeuten. Mit der Bestätigung auf OK erreichen wir den Vorraum des Foyers von Power Query:
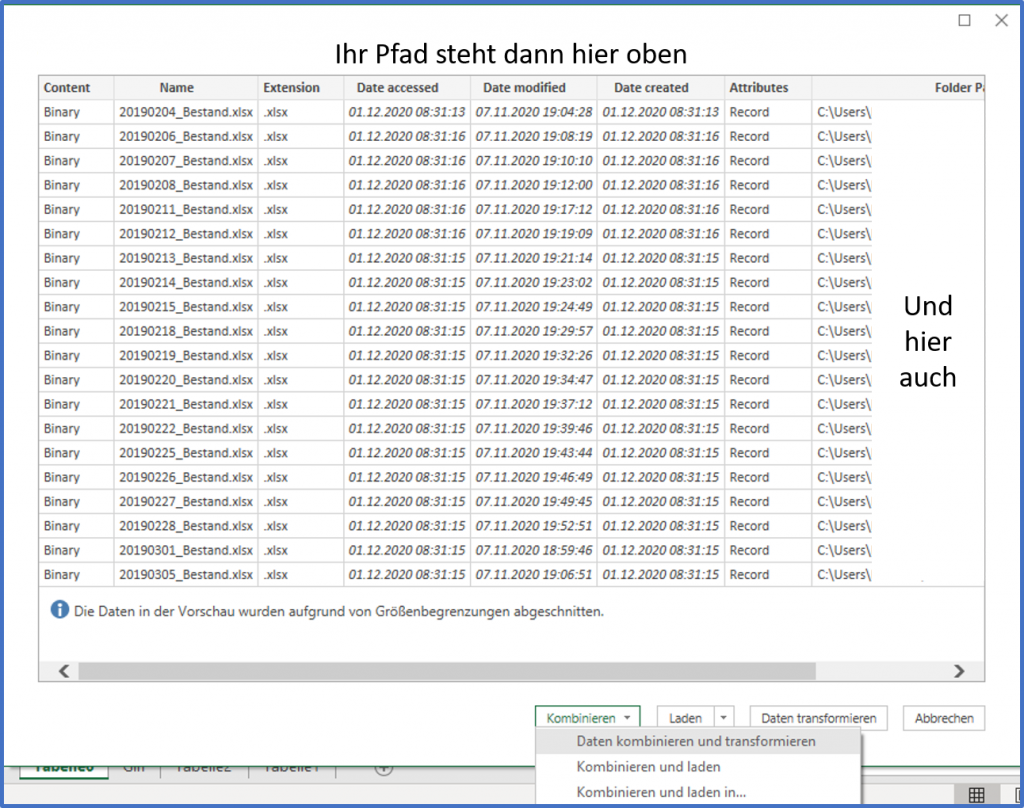
Wie Sie es von mir kennen, wollen wir die Daten natürlich nicht vorschnell ins Modell schmeißen, sondern erstmal gucken womit wir es zu tun haben. Über Daten kombinieren und transformieren begeben wir uns auf jenen Pfad. Die angezeigten Informationen des obigen Screenshots sollen uns für den Moment nicht weiter interessieren, wir nehmen diese zur Kenntnis, was es dann aber auch gewesen sein soll.
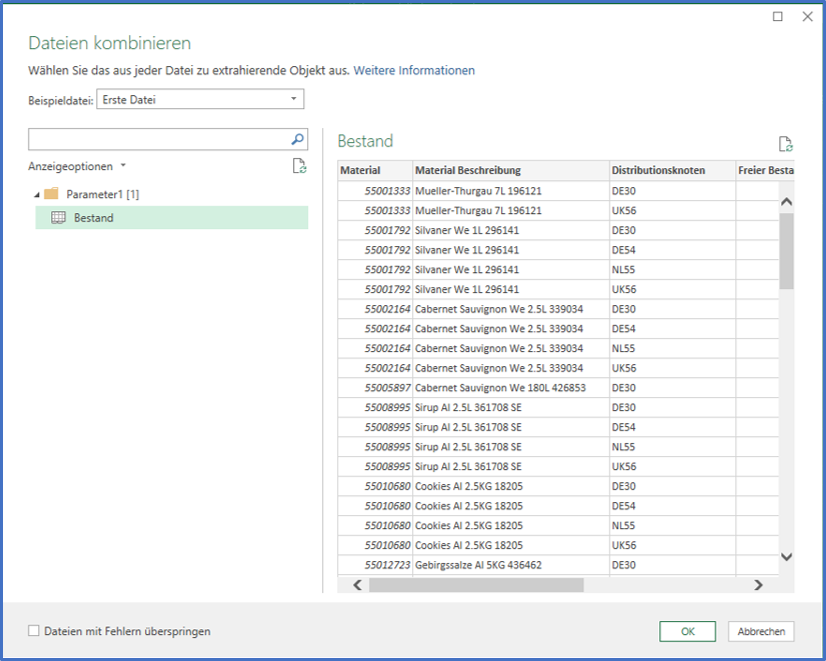
An dieser Stelle erlaubt uns Power Query zu bestimmen auf welcher Basis wir alle Dateien des Ordners formatieren möchten. Im alltäglichen Gebrauch belasse ich es eigentlich immer auf der Standardauswahl erste Datei, klicke auf OK und lande nun endlich im Hauptbereich des Tools.
Gut gemeinter Rat
Bevor es weiter geht ein, vielleicht zwei kleine Hinweise. Wenn Sie mit einem ERP-System wie SAP ECC, dem Oracle Pendant oder dem Erzeugnis einer anderen Klitsche arbeiten, empfehle ich Ihnen, sofern sie mit wiederkehrenden Datenauszügen der genannten Systeme arbeiten, sich Varianten anzulegen. Da ich bisher immer mit SAP arbeiten durfte, verwende ich den dort üblichen Begriff. Varianten ermöglichen es eine Transaktion des ERP-Systems immer in der gleichen Weise abzurufen. Hier können beispielsweise immer die gleiche Materialgruppe, ein Zeitraum oder ein gewisser Dokumentenkreis bestimmt werden. Außerdem besteht die Möglichkeit sein persönliches Datenlayout anzulegen. Am Ende aller Tage können Sie dadurch mit wenigen Klicks die gleichen Daten zu einem anderen Zeitpunkt herunterladen.
Nobody is perfect – Wenn Sie am Anfang einer Datenjäger und Sammler Aktion den Umfang der benötigten Daten noch nicht kennen, die Varianten angelegt und schon einige Dateien heruntergeladen haben, müssen Sie diese nicht verwerfen wenn eine weitere Spalte hinzukommen sollte! Power Query hat genügend Flexibilität und Dynamik um Ihnen unter die Arme zu greifen – keine Sorge!
Aus zwei versprochenen, wurden drei gut gemeinte Hinweise. Sollten Sie, wie in unserem behandelten Beispiel Daten in wiederkehrenden Zeitintervallen extrahieren, tun Sie sich den Gefallen auch das Downloaddatum zu hinterlegen. Das vereinfacht die Identifikation der Dateien und zerschnibbeln des Texts.
Wunderbar, nachdem Sie die Ratschläge verinnerlicht haben geht es weiter. Wir sehen, dass die erste Spalte der Übersicht den Quellnamen der Datei enthält, die wiederrum einen Datumsstempel im Namen trägt. Heute ist aber auch viel Glück im Spiel. Wie kommen wir jedoch an das Datum heran? Kennen Sie TEIL, LINKS, RECHTS, FINDEN, SUCHEN? Wenn ja, weiß ich, dass da der ein oder andere schmerzliche Vorfall in der Vergangenheit war. Wie zu erwarten, hilft uns das Tool diese Schmerzen zu vermeiden.
Erzeugen einer brauchbaren Datumsspalte
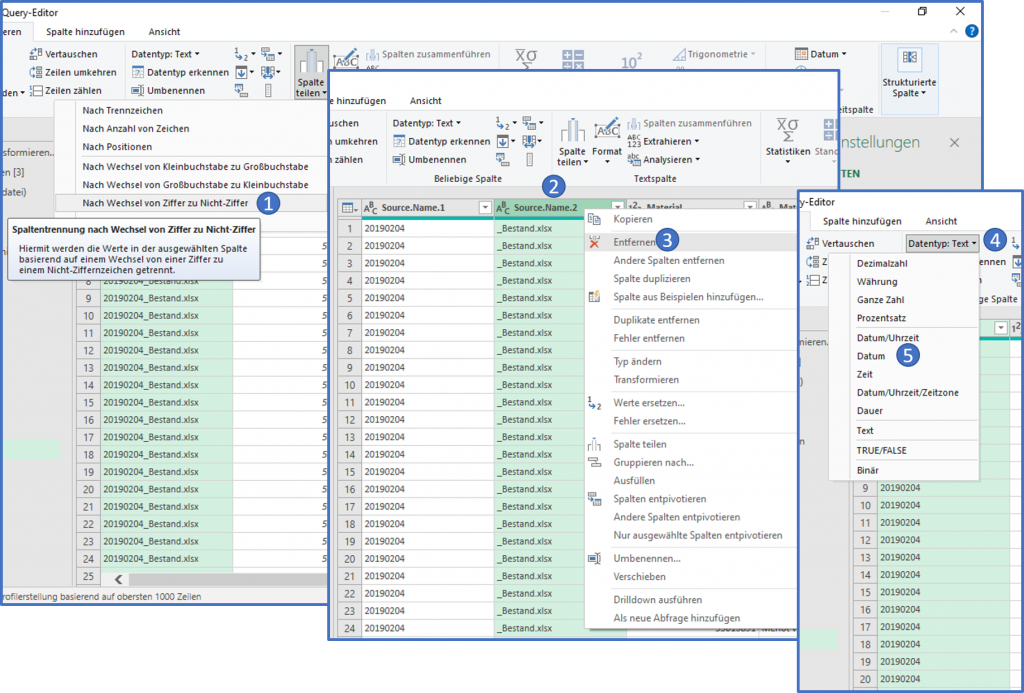
Zu Beginn müssen wir die erste Spalte teilen indem wir die Zahlen vom Text trennen. Power Query präsentiert uns diverse, vorgefertigte Optionen, von denen wir prompt eine verwenden werden. (1) In den nächsten Ansichten sehen wir, dass dies ohne große Mühen abläuft und wir am Ende eine saubere Datumsspalte haben, mit der wir im späteren Verlauf eine Beziehung zu unserer Datumstabelle herstellen möchten.
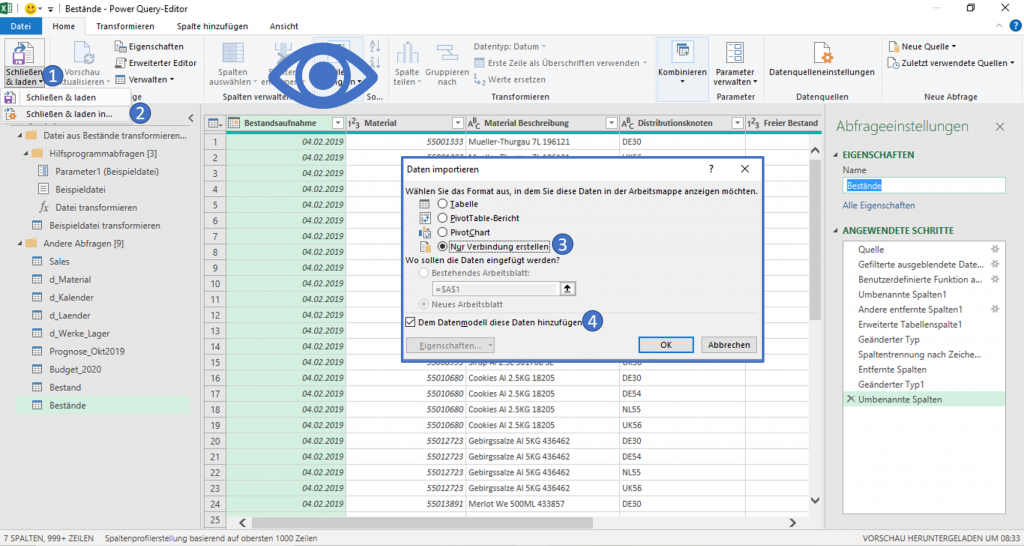
Unter dem, in seiner Ähnlichkeit nicht zu verkennenden Horusauge, befindet sich unsere tolle Datumsspalte, die wir in Windeseile einfach mal so für 130 Bestandsdateien festgelegt und somit erzeugt haben. Ich habe den Namen Bestandsaufnahme vergeben. Stellen Sie sich diese Aufgabe bitte ohne Power Query oder VBA Kenntnisse vor. Gute Nacht! Wir befolgen die aufgezeigten Schritte, wobei drei und vier in einem Fenster erfolgen, dass vor dem Hintergrund des Excelarbeitsblatts schwebt. Aus Platzgründen habe ich es hier hinterlegt. Nach kurzem Rattern der Dampfmaschine haben wir 815.729 Zeilen ins Datenmodell geladen.
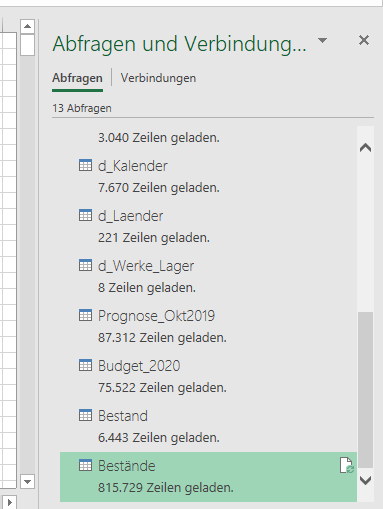
Beziehungen und zwei kleine neue Measures erstellen
Eine neue Tabelle ohne Beziehungen zu anderen, ist in Power Pivot und DAX ein eher seltenes Phänomen. Wir erstellen daher die Beziehungen zu unseren üblichen Dimensionstabellen d_Material, d_Kalender und d_Werke_Lager.
Darüberhinaus wollen wir zum Einstieg in die Bestände die Measures:[fr_LB_ST] und [akt_fr_LB_ST] erstellen. Das erste Measure summiert dabei lediglich alle freien Bestände über den gesamten Zeitraum auf. Letzteres nimmt immer nur den letzten gemeldeten Bestand als Summe:
[akt_fr_LB_ST]= CALCULATE([fr_LB_ST];LASTDATE(‘Bestände'[Bestandsaufnahme]))
LASTDATE ist eine Funktion, die eine Tabelle mit einer Zeile erstellt und diese als Filter in die CALCULATE Funktion einfließt. Mit diesen zwei schnell erstellten Measures können sie nun schon loslegen erste Bestandsgraphen zu erstellen:
Die alte, einzelne Bestandstabelle hat, dank unseres heutigen Kraftakts ausgedient und kann theoretisch gelöscht werden. Je nachdem zu welcher Tages oder Nachtzeit Sie den Artikel gelesen haben, können Sie sich sicherlich mit einem Getränk belohnen.
Bleiben Sie neugierig bei der Jagd nach Zahlen! Schönen Resttag.
#Formelwissen: LASTDATE

No responses yet